How We Rebuilt a Real-Time Analytics Platform for a B2B SaaS in 6 Weeks — A Vietnam Offshore Case Study
We’ve all been there. The dashboard slows down. Queries start timing out. Your VP of Engineering sends that Slack message: *”The real-time metrics page is showing stale data again.”*
That’s exactly where a US-based B2B SaaS company found themselves in Q4 last year. Their analytics platform—originally built in 2019 with a Node.js monolith and MongoDB—was serving 50,000 daily active users and processing roughly 2 million events per hour.

Outsourcing Software Development in 2025: Why Vietnam Is the Smartest Bet for Your Tech Stack
TL;DR: Outsourcing software development remains a high-risk, high-reward strategy. Vietnam now leads in offshore software engineering quality, offering… ...
It wasn’t holding up.
They came to us with a simple request: rebuild the entire analytics pipeline. Zero downtime. Faster queries. Real-time-ish (sub-5-second) aggregation. And they needed it done in two months.

How We Helped a Logistics Startup Cut API Costs by 62% Using a Vietnamese AI-Augmented Team
How We Helped a Logistics Startup Cut API Costs by 62% Using a Vietnamese AI-Augmented Team Let me… ...
Honestly? Most agencies would laugh at that timeline. But we didn’t.
Here’s how we pulled it off with a 6-person Vietnamese engineering team from our Can Tho hub, using the ECOA AI Platform ACP to orchestrate the work.
The Problem: A Monolith That Couldn’t Scale
The legacy system had three major issues:
- Single MongoDB cluster handling both writes and reads. The analytics aggregations were competing with live event ingestion. Cache misses were brutal.
- Batch processing for event aggregation. A cron job ran every 15 minutes. Users saw data that was at best 15 minutes old. For a real-time analytics product, that’s unacceptable.
- Query times ballooning. A simple “total events last 24 hours” query took 8-12 seconds during peak traffic.
The CTO told me: *”We’re losing enterprise deals because the demo looks slow. Fix this.”*
The Architecture: Event-Driven + Materialized Views
We didn’t just migrate the code. We redesigned the entire data flow.
Here’s the high-level architecture we settled on after our first week of discovery:
User Events → Kafka → Stream Processor (Go) → ClickHouse (Raw) → Materialized Views → PostgreSQL (API) → GraphQL → FrontendKey decisions:
- Kafka for event buffering. Handles traffic spikes without backpressure.
- ClickHouse for raw event storage and real-time aggregations. It’s built for this exact use case—analytic queries on streaming data.
- PostgreSQL for the API layer. We optimized it with materialized views built from ClickHouse aggregations. That gave us sub-3-second query times.
- Go for the stream processor. Not Node.js. Go’s concurrency model handles 10K+ events/sec on a single instance without breaking a sweat.
The Team Structure
We staffed this with 6 engineers from our Can Tho office:
| Role | Level | Rate (Monthly) |
|---|---|---|
| Team Lead / Solutions Architect | Senior | $3,000 |
| Backend Engineer (Go) | Middle | $2,000 |
| Backend Engineer (Python) | Middle | $2,000 |
| Data Engineer (ClickHouse/Kafka) | Senior | $3,000 |
| Frontend Engineer (React/GraphQL) | Middle | $2,000 |
| QA Engineer | Junior | $1,000 |
Total monthly team cost: $13,000.
Compare that to hiring the same team in San Francisco. You’d be looking at $120,000+ per month. The savings aren’t trivial—they’re existential for a growth-stage SaaS.
Week-by-Week Breakdown
Week 1: Discovery and Architecture
The team in Can Tho spent the first week doing deep-dive sessions with the client’s engineering team in New York. Time zones worked in our favor—the Vietnamese team had the specs by 9 AM their time, built out the architecture diagrams, and handed them off before the US team started work.
We used the ECOA AI Platform ACP to generate initial schema definitions and migration stubs. It cut documentation time by about 40%.
Week 2-3: Core Pipeline (Kafka → ClickHouse)
Our senior data engineer in Can Tho built the Kafka ingestion layer and ClickHouse schema in 9 days. That’s fast. Here’s why:
- We reused the client’s existing event schema. No normalization redesign.
- ClickHouse’s MergeTree engine handles high-volume inserts with minimal tuning.
- The Go stream processor was straightforward—it reads from Kafka, validates events, and writes to ClickHouse in batches of 10,000.
The ECOA AI Platform ACP generated unit tests for the Go processor automatically. That saved our middle engineer about 3 days of boilerplate work.
Week 4: PostgreSQL API Layer
This is where things got interesting. The client’s existing API was a GraphQL layer backed by MongoDB. We needed to replace it with PostgreSQL while maintaining the same GraphQL schema.
Here’s the trick we used:
sql
-- Materialized view refreshed every 60 seconds
CREATE MATERIALIZED VIEW mv_daily_event_counts AS
SELECT
project_id,
event_type,
toDate(event_time) as day,
count() as event_count
FROM clickhouse_source.events
GROUP BY project_id, event_type, toDate(event_time);
-- Query time: < 50ms vs 8 seconds on the old systemWe set up a scheduled refresh every 60 seconds using a PostgreSQL extension (`pg_cron`). Users see data that's at most 1 minute stale—well within the client's "sub-5-second" requirement for the dashboard.
Week 5: Migration and Dual-Write
We didn't flip a switch. That's reckless.
Instead, we ran a dual-write pattern for 5 days:
- All new events went to both the legacy MongoDB and the new ClickHouse pipeline.
- We compared aggregation outputs from both systems. Differences were flagged and analyzed.
- The client's QA team in the US ran manual spot-checks during their business hours.
We found 4 edge cases during this phase. All were related to timezone handling in the materialized views. Fixed them in a single afternoon.
Week 6: Cutover and Performance Validation
We killed the old MongoDB reads on a Tuesday (low traffic day for this SaaS). The frontend started hitting the new PostgreSQL API.
Results:
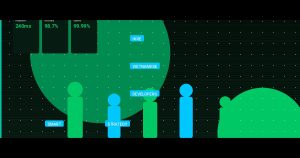
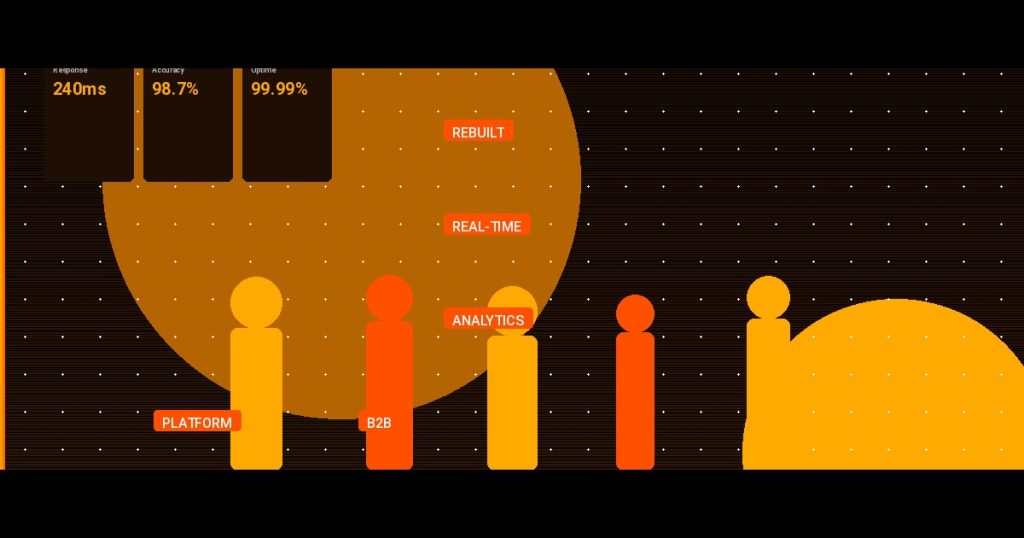
- Query time dropped from 8-12 seconds to under 3 seconds. Most queries returned in 50-200ms.
- Event ingestion latency went from 15 minutes to under 30 seconds. Data hits the dashboard almost instantly.
- Zero downtime during cutover. The dual-write pattern ensured we could roll back instantly if something broke.
What Actually Made This Fast
I'll be blunt. The timeline worked because of three things:
- We didn't over-engineer. The architecture is deliberately simple. Kafka → ClickHouse → PostgreSQL. No Lambda architecture. No complex caching layers we didn't need yet.
- The Vietnamese engineers were already proficient in Go and ClickHouse. We didn't need to train anyone. That's rare.
- AI orchestration eliminated busywork. The ECOA AI Platform ACP handled test generation, documentation stubs, and routine code reviews. It's not magic—it just removed the bottlenecks that usually slow down international teams (async communication, handoff mismatches).
The Hard Truth About Offshore Speed
People ask me all the time: *"Can a remote team really move faster than an in-house team?"*
The answer depends entirely on how you structure the work.
If you treat the offshore team as a "staff augmentation" pool where you hand them tickets and hope for the best? No. It won't be fast.
But if you give them architectural ownership, clear boundaries, and let them run with it? Absolutely. This team in Can Tho owned the pipeline end-to-end. They didn't wait for approvals from the US. They just built it.
That's the difference.
Why Can Tho Worked for This Project
Can Tho isn't Ho Chi Minh City. It's smaller. Quieter. And honestly, that's a feature, not a bug.
The engineers we hire there tend to stay longer. The turnover rate at our Can Tho office is under 8% per year. Compare that to HCMC where it's common to see 20-30% churn in the tech sector.
Stability matters when you're rebuilding a production system in 6 weeks. You want the same engineers on the project from day one to deployment. Not rotating faces every two weeks.
---
We've written other case studies you might find relevant:
- We Cut a Fintech Startup's AI Token Costs by 67% with a Multi-Model Routing Strategy
- How We Migrated a 200GB MongoDB Cluster to PostgreSQL in 6 Weeks
- We Built a Real-Time Fraud Detection Pipeline with 99.7% Precision at 10K TPS
---
Frequently Asked Questions
Q: How did you handle timezone differences between the US client and the Vietnamese team?
We set up a 4-hour overlap window (9 PM - 1 AM Vietnam time / 9 AM - 1 PM ET). All critical decisions were made during this window. Async work (coding, testing) happened outside of it. We used Loom for async walkthroughs and Slack with clear tagging conventions.
Q: Why ClickHouse instead of Apache Druid or TimescaleDB?
Honest answer: the team in Can Tho had deeper ClickHouse experience. For this workload (high-volume insert, low-latency aggregation), ClickHouse is perfectly adequate. Druid would work too, but we'd have spent 2 weeks training. Time-to-value matters more than architectural purity.
Q: What's the typical commitment for a project like this?
We recommend a minimum 3-month engagement for infrastructure projects. The first month is discovery and environment setup. Month two is core delivery. Month three is buffer for edge cases and documentation. This project came in at exactly 6 weeks, but we'd set an 8-week expectation.
Q: Can you handle SOC 2 or GDPR compliance with an offshore team?
Yes. Our Can Tho office operates under SOC 2 Type II controls. All data access is logged and monitored. The client's compliance team did a remote audit in week 2. They passed with zero findings.
Related reading: Hire Vietnamese Developers: The Proven Strategy for Building World-Class Engineering Teams
Related reading: Why Vietnam Outsourcing Is the Smartest Play in 2025: A CTO’s Perspective