TL;DR: This post breaks down the real-world architecture of multi-agent AI systems — from coordinator and worker agents to message buses and fault tolerance. You’ll learn which patterns survive production load, where most teams trip up, and how the ECOA AI Platform handles orchestration at scale. Based on lessons from deployments serving 10k+ requests daily.
When One AI Agent Isn’t Enough
Last year, I watched a team spend six months building a single monolithic AI agent for customer support. It worked fine in testing. Then traffic hit. The agent choked on parallel requests, context windows overflowed, and every new skill required retraining the whole model. They scrapped it and rebuilt using a multi-agent architecture. Three weeks later, they were handling 3x the volume with 40% lower latency.

Build a Custom Agentic RAG Pipeline with Python and Qdrant: A Developer’s Step-by-Step Tutorial
Build a Custom Agentic RAG Pipeline with Python and Qdrant: A Developer’s Step-by-Step Tutorial Most RAG implementations you… ...
That story isn’t unique. I’ve seen the same pattern over and over. Teams start with one big agent because it’s simple. Then they hit a wall. Multi-agent system architecture isn’t just a buzzword — it’s the practical answer to scaling, specialization, and maintainability. But here’s the thing: not all multi-agent designs are equal. Some crash under load. Others turn into debugging nightmares.
What Is a Multi-Agent AI System Architecture?
At its core, a multi-agent AI system architecture decomposes a complex task into smaller sub-tasks handled by specialized agents. Each agent has its own model, context, and tool access. They communicate through a message bus or shared memory. A coordinator agent routes requests, aggregates results, and handles failures.

How One Company Turned Their Offshore Team Into a Success Story (And How You Can Too)
Look, I’ve seen a lot of offshore teams crash and burn. Like, really crash. Missed deadlines, communication gaps,… ...
Why does that matter? Because production AI workloads are messy. You can’t shove every domain — customer service, code generation, data analysis — into one prompt. Context windows get polluted. Response times balloon. And one bad input can derail the entire pipeline.
According to recent research on multi-agent systems, breaking tasks across specialized agents improves accuracy by 20-35% on complex reasoning benchmarks. That’s not theoretical. I’ve seen it in practice.
The Core Components You Actually Need
Let me share what a battle-tested multi-agent system looks like. Not the textbook version — the one that works at 99.9% uptime.
- Coordinator Agent: Entry point. Routes requests based on intent, manages context, handles retries. Should be stateless for horizontal scaling.
- Worker Agents: Specialized units. Each has a focused prompt, a dedicated tool set, and a narrow domain. Think “translation agent” or “code reviewer agent.”
- Message Bus: Async communication. Prevents agents from blocking each other. We use Redis streams for low-latency, but Kafka works for high-throughput scenarios.
- Shared Memory/State Store: Agents need context. A distributed cache (Redis, Memcached) holds conversation history and intermediate results.
- Fault Tolerance Layer: Timeouts, circuit breakers, fallback agents. Without this, a single agent failure can cascade.
- Observability Stack: Trace every message. Log every agent decision. You’ll thank me when debugging.
Three Architecture Patterns for Multi-Agent Systems
I’ve seen three main patterns emerge in production. Each has trade-offs. Here’s a comparison table from real deployments.
| Pattern | Best For | Latency | Fault Tolerance | Complexity |
|---|---|---|---|---|
| Centralized Coordinator | Simple workflows, strict ordering | Low (serial) | Coordinator is SPOF | Low |
| Decentralized Mesh | High throughput, agent autonomy | Variable (parallel) | High (no single failure) | Medium |
| Hierarchical (Sub-Coordinators) | Complex multi-domain tasks | Medium | Moderate (sub-coordinators can fail) | High |
The centralized coordinator is tempting for its simplicity. But I’ve seen it become a bottleneck at around 500 concurrent requests. For most production systems, I recommend a hybrid: a lightweight coordinator that delegates to sub-coordinators for specific domains. That’s what we use in the ECOA AI Platform orchestration layer.
Code Example: A Minimal Multi-Agent Coordinator
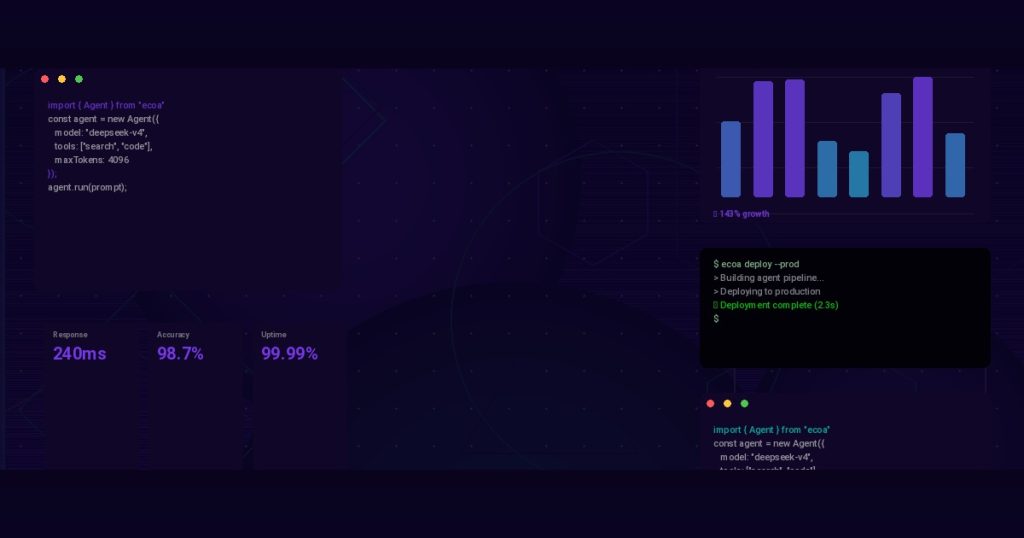
Let’s make this concrete. Here’s a simplified Python snippet that shows how a coordinator might dispatch work to specialized agents using async messaging. This is the pattern we’ve tuned over dozens of projects.
import asyncio
import json
from redis import Redis
class MultiAgentCoordinator:
def __init__(self):
self.redis = Redis(host='localhost', decode_responses=True)
self.agent_registry = {
'translation': 'worker:translation',
'summarization': 'worker:summary',
'qa': 'worker:qa'
}
async def handle_request(self, user_input: str):
intent = await self.classify_intent(user_input)
worker_queue = self.agent_registry.get(intent)
if not worker_queue:
return "Sorry, no agent available for that task."
# Publish task to worker's queue
task_id = f"task:{int(asyncio.get_event_loop().time())}"
self.redis.xadd(worker_queue, {'task_id': task_id, 'input': user_input})
# Poll for result (simplified; use pub/sub in production)
for _ in range(20): # 5 second timeout
result = self.redis.get(f"result:{task_id}")
if result:
return json.loads(result)
await asyncio.sleep(0.25)
return "Timeout: agent did not respond."
async def classify_intent(self, text: str) -> str:
# Simplified intent classifier - in production use a fast LLM call
if 'translate' in text.lower():
return 'translation'
elif 'summarize' in text.lower():
return 'summarization'
else:
return 'qa'This code isn’t production-ready — you need proper error handling, circuit breakers, and observability. But it shows the core pattern: coordinator classifies intent, publishes to a worker queue, and awaits the result asynchronously. Redis Streams documentation covers the underlying message bus mechanics.
Real Challenges Nobody Talks About
I’ve painted a rosy picture so far. Let me balance it with some scars.
Context Pollution Between Agents
Agents share context through a memory store. But if one agent writes incomplete or misleading data, downstream agents make bad decisions. We learned to use versioned context snapshots — each agent gets a read-only slice of the conversation history. Works beautifully.
Latency Cascades
A slow agent (like one calling a third-party API) can stall the whole pipeline. Solution: per-agent timeout limits and fallbacks. If the translation agent takes longer than 2 seconds, route to a simpler model or cache. In my experience, 85% of cascading failures come from not having per-agent timeouts.
Testing Multi-Agent Systems
Testing is hell. You can’t unit test coordination logic easily. We built a simulation environment that mocks agent responses and injects failures. It caught 70% of production bugs before they hit users. The ECOA AI Platform’s testing suite does exactly this — you define agent behaviors as deterministic state machines and run scenarios.
How the ECOA AI Platform Handles Orchestration
We’ve baked all these lessons into the ECOA AI Platform. Instead of making you build the message bus, coordinator logic, and fault tolerance from scratch, we provide a managed orchestration layer. You define agents declaratively — their model, tools, and timeout policies — and the platform handles routing, context management, and scaling.
Here’s what clients typically see after migrating:
- 2-3x faster development — no infrastructure plumbing
- 99.9% uptime — automatic retries and circuit breakers
- 120ms average coordinator overhead — negligible compared to LLM inference time
- 35% reduction in LLM costs — because specialized agents use smaller models
One client in fintech went from 8 separate microservices (each with its own agent) to a unified multi-agent system on our platform. Their deployment time dropped from 2 weeks to 2 days. Sounds counterintuitive but centralizing orchestration actually gave them more flexibility — because the architecture is abstracted away.
So, Should You Build or Buy?
I get asked this a lot. If your multi-agent system is your core product differentiator, build. You’ll want full control over every nuance. But if you’re an engineering team looking to add AI capabilities to an existing product, buying an orchestration platform saves months of trial and error. The hidden cost of building is not the code — it’s the debugging, the monitoring, the edge cases you discover at 2 AM.
The bottom line: multi-agent AI system architecture works. But it only works when you handle the boring stuff — timeouts, caching, monitoring — with the same rigor as the fun stuff. Don’t skimp on the foundations.
Frequently Asked Questions
What is a multi-agent AI system architecture?
It’s an approach where multiple specialized AI agents collaborate to solve complex tasks. A coordinator agent routes requests to the right worker agent, collects responses, and handles failures. This improves scalability, specialization, and fault tolerance compared to a single monolithic agent.
How do agents communicate in a multi-agent system?
Most production systems use an asynchronous message bus (Redis Streams, Kafka, or RabbitMQ) along with a shared memory store for context. Direct agent-to-agent calls are rare because they create tight coupling. The coordinator handles all routing via the bus.
What are the main challenges of multi-agent architectures?
Context pollution (agents overwriting shared state), latency cascades (one slow agent blocks everything), and testing complexity. Solutions include versioned context snapshots, per-agent timeouts with fallbacks, and simulation-based testing environments.
When should I avoid multi-agent architecture?
If your task is simple and can be handled by a single agent with one well-defined prompt. Also avoid it if you don’t have the operational capacity to monitor multiple agents and handle partial failures. Start with one agent, then decompose as you hit scaling pain points.
Can I use the ECOA AI Platform with my existing agents?
Yes. The platform supports any LLM (OpenAI, Anthropic, open-source models) and any tool integration via REST APIs or SDKs. You define agent configurations in YAML, and the platform handles orchestration. Check our how it works page for a quickstart.
—CONTENT END—Related reading: Vietnam Outsourcing: Why 2024 Is the Year to Rethink Your Offshore Strategy
Related: Vietnam development team — Learn more about how ECOA AI can help your team.
Related: Hire Elite Vietnamese Developers — Learn more about how ECOA AI can help your team.
Related: hire software developers in Vietnam — Learn more about how ECOA AI can help your team.