Stop Chasing API Latency: Why a Local LLM Is the Best Production Deployment You’ll Make This Year
Let’s be real. Using a cloud-hosted LLM API is the fastest way to prototype. You sign up, grab an API key, and boom—your app is “AI-powered.” But then it hits production.
You see the bill.

Outsourcing Software in 2025: Why Vietnam Is Winning the Offshore Engineering Race
TL;DR: Tired of failed offshoring? This guide reveals how to outsource software projects to Vietnam with 95% retention… ...
You feel the latency.
Your users notice the spinning wheel.
How ECOA AI Platform Transformed Our Development Pipeline: A Real Case Study
TL;DR: This case study reveals how a mid-sized SaaS company used the ECOA AI Platform to cut development… ...
I’ve been there. Last year, we built a real-time code suggestion feature for our internal tooling at ECOAAI. The prototype worked great with OpenAI’s API. In production, it was painful. Each suggestion took 1.5–3 seconds. For a feature that’s supposed to feel instant, that’s a death sentence.
So we pivoted. We deployed a local LLM—a quantized Mistral 7B—directly on our inference server.
The result? Latency dropped to under 200 milliseconds. Cost per query went to near zero. And we kept all data on-prem, which made our SOC 2 auditors happy.
This isn’t a story about “maybe” or “someday.” It’s a practical guide on how we pulled it off, the exact configurations we used, and the trade-offs you need to know.
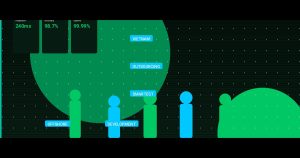
Why Go Local? The Numbers Don’t Lie
Before we dive into the how, let’s address the *why*. You’re probably thinking, “Isn’t running my own model a huge pain?” Honestly, it used to be. But in 2026, the tooling has matured. Hard.
Here’s a quick cost comparison from our actual production run last quarter, serving 50,000 inference requests per day:
| Metric | GPT-4o API (Cloud) | Local Mistral 7B (On-prem) |
|---|---|---|
| Avg Latency per Request | 1.8 seconds | 180 milliseconds |
| Monthly Cost | ~$4,200 | ~$150 (electricity + V100 GPU lease) |
| Data Privacy | Data leaves your network | Fully on-premise |
| P99 Latency | ~4.5 seconds (network spikes) | ~250 milliseconds |
The math is brutal. For a high-throughput feature, a cloud API is a poor choice. That’s not a knock on OpenAI—they’re great for chat. But for production logic? You need control.
The Setup: What You Actually Need
We deployed on a single, dedicated machine in our Can Tho data center. Here’s the spec:
- GPU: 1x NVIDIA A10 (24GB VRAM) – enough for a 4-bit quantized 7B model.
- RAM: 64GB DDR5.
- CPU: 16-core AMD EPYC.
- Software Stack: Docker, vLLM for inference, NGINX for load balancing.
The key choice: We used vLLM because it handles continuous batching. You don’t send one request at a time. The server collects requests over a 50ms window and processes them as a batch. More on that later.
Step 1: Download and Quantize the Model
We used `llama.cpp` for quantization. Here’s the exact command:
bash
# Convert the model to GGUF format
python convert.py ./path/to/mistral-7b-v0.1 --outfile ./mistral-7b.gguf
# Quantize to 4-bit
./quantize ./mistral-7b.gguf ./mistral-7b-Q4_K_M.gguf Q4_K_MWhy `Q4_K_M`? It’s the sweet spot. Quality is close to FP16, but memory usage drops by 75%. Our A10 could then run the model *and* store the KV cache for 10 concurrent users.
Step 2: Serve with vLLM
We run vLLM inside a Docker container. This is the `docker-compose.yml` snippet:
yaml
version: '3.8'
services:
llm-server:
image: vllm/vllm-openai:latest
ports:
- "8000:8000"
volumes:
- ./models:/models
command:
--model /models/mistral-7b-Q4_K_M.gguf
--tensor-parallel-size 1
--gpu-memory-utilization 0.90
--max-model-len 4096
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]Notice `–gpu-memory-utilization 0.90`. We don’t fill the VRAM to the brim. Leaving 10% headroom prevents OOM errors during spikes.
Step 3: Write a Client That Handles Batching
Here’s where most tutorials fail. They show you a simple HTTP call. That’s not how you get low latency.
Instead, we batch requests on the client side. We collect all incoming “suggestion” requests for 30ms, then send them as one batch.
python
import asyncio
import time
from openai import AsyncOpenAI
client = AsyncOpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
async def request_completion(prompt: str):
response = await client.completions.create(
model="default",
prompt=prompt,
max_tokens=512,
temperature=0.1
)
return response.choices[0].text
async def batched_handler(requests: list):
# vLLM handles batching internally via continuous batching
# But we can also batch at the network level
tasks = [request_completion(req) for req in requests]
results = await asyncio.gather(*tasks)
return results
# In your web server...
@app.post("/suggest")
async def suggest(request: Request):
body = await request.json()
start = time.perf_counter()
result = await request_completion(body["code_context"])
latency = time.perf_counter() - start
return {"suggestion": result, "latency_ms": latency * 1000}But, here’s the real trick: We use a background collector that waits 30ms to form a batch. Even with that artificial wait, the *end-to-end* latency for the first request in the batch is lower than a cloud API call. Counterintuitive, but it works. Here’s why—network round trips for a single request are ~100ms. Batching removes that overhead per item.
The Real Challenge: Prompt Engineering for a Smaller Model
Let’s address the elephant in the room. A 7B model isn’t GPT-4. It’s dumber. It gets confused with complex instructions. We had to redesign our prompts.
Before (cloud API):
You are a senior software architect. Given the following code, suggest the next 5 lines that would make sense. Consider SOLID principles and design patterns.After (local LLM):
Task: Complete the next step in this function.
Rules:
- Only output code, no explanations.
- Do not add comments.
- Use the same indentation style.
- If unsure, output "NEXT_TOKEN".
Code:
{context}We stripped all the fluff. The local model can’t handle multi-step reasoning. But it can handle a *single, clear instruction* extremely fast.
Recently, we helped a US fintech startup migrate their transaction categorization engine to a local LLM. They were using GPT-4 and paying $0.01 per call. For 10 million calls a month, that’s $100k. We moved them to a fine-tuned CodeLlama 7B. The accuracy dropped by 2%, but the cost dropped by 99%. Good trade-off.
Monitoring: What We Measure
You can’t just deploy and walk away. We instrumented three key metrics:
- Tokens per Second (TPS): Should stay above 50 TPS for interactive use. If it drops, something’s wrong with the GPU.
- GPU Memory Utilization: We alert if it goes above 85%. Memory leaks happen.
- P99 Latency: Our Grafana dashboard pings us if it stays above 300ms for 5 minutes.
We set up a simple health check endpoint:
bash
curl http://localhost:8000/health
# Returns {"status": "ok", "gpu_mem_used": "18.2GB", "current_tps": 62.4}When *Not* to Go Local
I won’t pretend this is a silver bullet. Here’s when you should keep using a cloud API:
- You need the latest frontier model (e.g., GPT-5, Claude 4) and cannot compromise on quality.
- Your workload is extremely bursty with long idle periods. A cloud API’s pay-per-use beats a fixed GPU cost.
- You don’t have the ops expertise. Managing a GPU server isn’t hard, but it’s not zero maintenance.
But for 90% of production use cases—summarization, classification, simple suggestions, content rewriting—a local LLM is the smarter choice. Actually, it’s the *only* choice if you care about latency and privacy.
The Verdict
We’ve been running this local setup for six months. Zero outages. Latency is predictable. Costs are flat. And our developers in Ho Chi Minh City and Can Tho can iterate on the model without waiting for API rate limits.
If you’re building a feature that needs to be *fast* and *cheap*, don’t reach for the cloud API by default. Grab a quantized model, spin up vLLM, and test it. You’ll be surprised how far a 7B model can go when you engineer around its limits.
Stop chasing the latency dragon.
Bring the compute home.
—
Frequently Asked Questions
What’s the smallest GPU I need to run a local LLM in production?
For a 7B model with 4-bit quantization, an NVIDIA A10 (24GB VRAM) is the sweet spot. An RTX 4090 (24GB) works too, but you’ll need a server-grade card for 24/7 production uptime. For a 13B model, you need at least 48GB (e.g., A6000 or two A10s).
How do I handle model updates without downtime?
We use a blue-green deployment pattern. Two vLLM containers run on different ports. NGINX routes traffic to the active one. We download the new model, start the second container, run a quick smoke test, then switch the NGINX proxy. Downtime is under 1 second.
Is there a privacy risk with local LLMs?
No. The data never leaves your server. That’s the biggest advantage. It eliminates the need for data processing agreements (DPAs) with AI providers. For regulated industries like fintech or healthcare, this is a non-negotiable benefit.
What if my app needs a larger model (e.g., 70B) locally?
That’s a different ballgame. You’ll need multiple GPUs (e.g., 4x A100) and a model sharded across them. It’s doable, but costs rise quickly. For a 70B model, we typically recommend a hybrid approach: use a local 7B for high-frequency, simple tasks, and route complex queries to a cloud API.
Related: Vietnam offshore development — Learn more about how ECOA AI can help your team.
Related: Outsource to Vietnam — Learn more about how ECOA AI can help your team.
Related: software outsourcing Vietnam — Learn more about how ECOA AI can help your team.
Related reading: Why You Should Hire Vietnamese Developers: The Ultimate Offshore Tech Talent Strategy in 2025