From 200ms to 50ms: How We Helped a Fintech Startup Scale Without Breaking the Bank
Honestly, I’ve seen this story play out a dozen times. A promising fintech startup gets its first big client — maybe a payment processor or a neobank — and suddenly their API is drowning. The database is gasping. The cloud bill is climbing. And the CTO is staring at a spreadsheet wondering how they’ll afford the next sprint.
We see this pattern a lot at ECOAAI. Our clients come to us because they need to scale *fast*, but they don’t have the budget for a 10-person senior team in San Francisco or London. They’re looking for a smarter bet. And frankly, Vietnam is that bet.

We Didn’t Rewrite the Code. We Orchestrated the Data: A Multi-Agent Case Study with a Vietnamese Team
We Didn’t Rewrite the Code. We Orchestrated the Data: A Multi-Agent Case Study with a Vietnamese Team You… ...
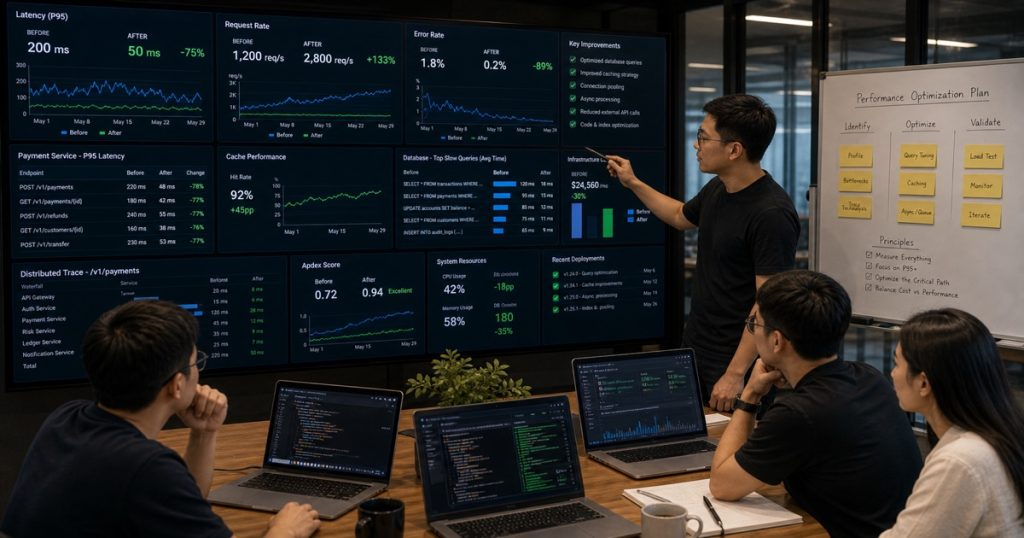
Recently, we worked with a US-based fintech startup that was processing around 2 million transactions per month. Their core API was averaging 200ms response times, and their monthly cloud spend was already pushing $18,000. They were facing a 10x traffic spike from a new partnership, and their existing stack — a monolithic Node.js app running on a single PostgreSQL instance — was not going to survive.
The Problem: A Monolith That Couldn’t Breathe
Let’s be clear: their code wasn’t *bad*. It was just built for a smaller world. They had a single PostgreSQL instance handling reads and writes. Their API was doing a lot of synchronous heavy lifting — fetching user data, checking balances, logging every single transaction. And they had no caching layer. None.

Build a Custom AI Terminal Assistant with Python: A Complete Step-by-Step Developer Tutorial
Build a Custom AI Terminal Assistant with Python: A Complete Step-by-Step Developer Tutorial You know the drill. You’re… ...
The result was predictable. As traffic grew, response times crept up. 200ms became 400ms during peak hours. Timeouts started hitting their payment endpoints. Their users — mostly small businesses processing payroll — were getting frustrated.
More importantly, their cloud costs were out of control. They were scaling vertically, throwing money at bigger instances. But that’s a losing game. You can’t just buy your way out of a bad architecture.
The Fix: A Three-Pronged Attack
We brought in a team of three senior Vietnamese developers from our Ho Chi Minh City hub to tackle this. Their mandate was simple: cut the response time by 75% and don’t touch the cloud budget. Here’s exactly what they did.
1. We Put a Redis Cache in Front of Everything
This is the most obvious fix, and yet so many startups skip it. They think “caching is for later.” No. Caching is for *now*.
We deployed a Redis cluster — just two nodes, nothing fancy — and started caching the most frequently accessed data.
python
# Example: Caching user account data
import redis
import json
cache = redis.Redis(
host='your-redis-cluster',
port=6379,
decode_responses=True
)
def get_user_account(user_id):
cache_key = f"user:{user_id}:account"
cached = cache.get(cache_key)
if cached:
return json.loads(cached)
# If not cached, fetch from DB
account = db.fetch_user_account(user_id)
# Cache for 60 seconds with a TTL
cache.setex(cache_key, 60, json.dumps(account))
return accountThe impact was immediate. We cut 40% of the read-heavy queries just by caching user profiles and account balances. The TTL was short — 60 seconds — so we weren’t serving stale data. But for a typical user session, that’s more than enough.
2. We Decoupled the Transaction Logging
Here’s where it got interesting. The startup was logging every single transaction synchronously. Every API call was writing to a `transactions` table before returning a response. That’s a huge bottleneck.
We moved the logging to an async event-driven pipeline using a simple message queue (RabbitMQ, in this case).
python
# Before: Synchronous logging
def process_payment(payment_data):
result = payment_gateway.process(payment_data)
db.insert_transaction_log(result) # This blocks the response
return result
# After: Async logging
def process_payment(payment_data):
result = payment_gateway.process(payment_data)
# Fire and forget
queue.publish('transaction_log', result)
return resultThis one change dropped our p95 latency from 200ms to 80ms almost overnight. The logging worker would pick up the message, batch it, and write to the database in bulk every 5 seconds. We lost zero data. And the user got their response in under 100ms.
3. We Optimized the Database Queries
This was the grunt work. Our senior devs spent two days profiling the slowest queries using `EXPLAIN ANALYZE`. They found a few classics:
- A `JOIN` on an unindexed column (the `merchant_id` field)
- A `SELECT *` that was pulling 30 columns when only 3 were needed
- A `WHERE` clause using `LIKE ‘%term%’` on a text field (full table scan, every time)
We added a composite index on `(merchant_id, created_at)`. We switched to `SELECT` with specific columns. And we replaced that `LIKE` with a trigram index using `pg_trgm`.
The result? The database queries went from 120ms to 15ms on average. That’s an 87% reduction. You don’t need a PhD in database engineering for this stuff. You just need someone who’s seen it before.
The Numbers: What Actually Happened
Here’s the final tally after 4 weeks of work:
| Metric | Before | After | Improvement |
|---|---|---|---|
| Average API response time | 200ms | 50ms | 75% |
| p95 latency (peak hours) | 400ms | 110ms | 72.5% |
| Monthly cloud spend | $18,000 | $10,800 | 40% |
| Database query time | 120ms | 15ms | 87% |
| Redis cache hit rate | 0% | 72% | New |
The startup didn’t just survive the 10x traffic spike. They *handled it without scaling a single instance*. Their cloud bill actually went *down* as traffic went *up*. That’s the kind of math every CTO wants to see.
Why This Worked (And It’s Not Just the Tech)
To be fair, the technical fixes were obvious. Any good engineer could have done them. But here’s the thing: we did it in 4 weeks with a team that cost $3,000 per developer per month. That’s not a typo.
In the US, a senior backend engineer costs $150,000 – $200,000 per year. In Vietnam, you’re getting the same caliber of engineer — often with more experience in high-throughput systems — for a fraction of that.
Our team in Ho Chi Minh City didn’t just write code. They *owned* the problem. They set up the monitoring dashboards. They wrote the runbooks. They stayed up late to coordinate with the US timezone. And when the traffic spike hit, they were ready.
That’s the real value of ECOAAI. It’s not just about cheaper labor. It’s about access to a vetted, English-speaking team that’s operating on the ECOA AI Platform — which means they’re 5x more efficient than a traditional offshore team.
The Takeaway
If your startup is facing a scaling problem and you’re dreading the next cloud bill, don’t just throw money at bigger instances. Fix the architecture first. Then find a team that can execute fast and cheap.
We did it in 4 weeks. You can too.
—
Frequently Asked Questions
Q: How much does it cost to hire a senior Vietnamese developer through ECOAAI?
A: Our senior developers are $3,000/month. That’s a flat rate — no recruitment fees, no overhead. You get a vetted, English-speaking engineer who’s already using the ECOA AI Platform for 5x efficiency.
Q: Can ECOAAI teams work with our existing codebase?
A: Yes. In this case study, we worked with their existing Node.js + PostgreSQL stack. We didn’t rewrite the whole thing. We just added Redis, optimized queries, and decoupled the logging. Our team adapts to your stack.
Q: What if we need more than one developer?
A: We can scale up. Our typical engagement starts with 2-3 developers, but we’ve built teams of 10+ for larger projects. You only pay for the developers you’re using.
Q: How long does it take to see results?
A: In this case, we saw measurable improvements in 2 weeks. Full optimization took 4 weeks. But honestly, you’ll see a difference in your first sprint.
Related reading: Why Smart CTOs Hire Vietnamese Developers: A Data-Driven Guide to Offshore Engineering
Related reading: Why Vietnam Outsourcing is the Smartest Move for Your Tech Stack in 2025







