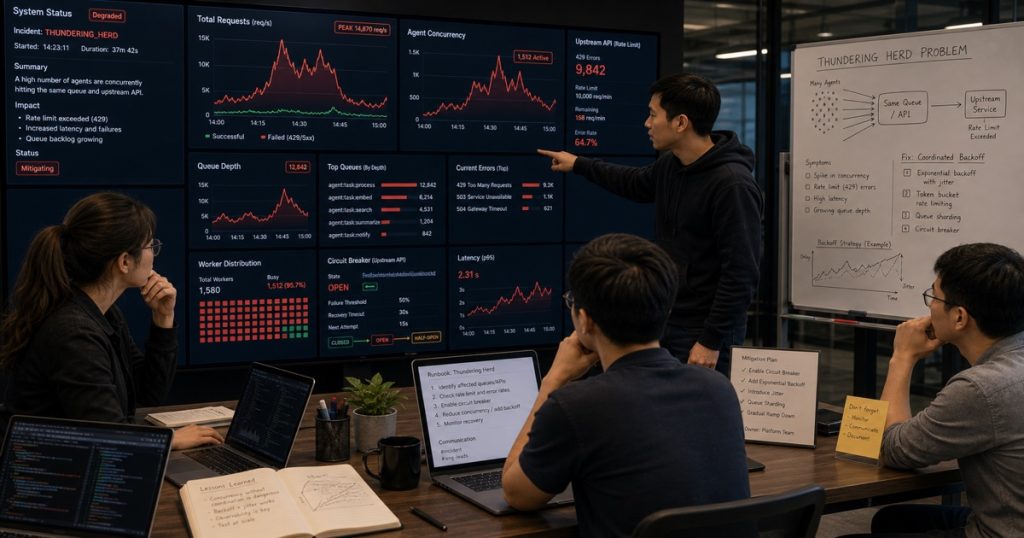
The Multi-Agent Thundering Herd Problem (And How We Fixed It with a Vietnamese Team)
You’ve built your multi-agent system. Agents are running. They’re smart. They’re fast.
Then production hits you with a wall.

Outsourcing Software in 2025: Why Smart CTOs Are Ditching the Old Playbook
TL;DR: Outsourcing software isn’t what it used to be. The old “cheap labor” model is dead. Today, successful… ...
All your agents suddenly fail at the exact same moment. Not because they’re buggy. Not because your LLM provider went down. But because they all tried to call the same rate-limited API at once.
Classic thundering herd. And it’s brutal.
Why Vietnam Outsourcing Is the Smartest Bet for Offshore Software Development in 2025
TL;DR: Vietnam is rapidly becoming the go-to destination for software outsourcing. Lower costs, a young tech-savvy workforce, strong… ...
What Actually Happens
Here’s the scenario we ran into. We had 200 specialized agents processing customer support tickets for a US-based e-commerce client. Each agent needed to check a third-party inventory API before generating a response.
The API allowed 100 requests per minute. Our agents? They’d all wake up simultaneously when a batch of 500 tickets dropped.
In the first 3 seconds, 200 agents slammed that endpoint. 100 requests succeeded. The other 100 got HTTP 429 responses. Then those 100 retried — all at once — 3 seconds later.
You see the pattern. It’s a cascade of failure.
Honestly, it was embarrassing. We’d built this beautiful orchestration layer. Smart routing. Context injection. Error recovery. And it all collapsed because we forgot one thing: coordination at the resource level.
Why Standard Rate Limiting Isn’t Enough
Most teams slap a retry-with-backoff on their agents. That’s fine for a single process. But in a distributed multi-agent system, each agent has no idea what the others are doing.
Agent A sleeps for 5 seconds. Agent B sleeps for 5 seconds. They wake up simultaneously and slam the API again.
Here’s the thing: exponential backoff doesn’t help when all agents start their backoff at the same time. You need a shared coordination mechanism.
The Fix: Distributed Semaphore with Redis
We solved this with a distributed semaphore using Redis. Every agent, before hitting the API, had to acquire a token from a shared pool. If no tokens were available, the agent waited — and I mean *actually waited*, not busy-polled.
Here’s the core implementation we used:
python
import redis.asyncio as redis
import asyncio
from typing import Optional
class DistributedSemaphore:
def __init__(self, redis_client: redis.Redis, name: str, max_tokens: int, ttl: int = 10):
self.redis = redis_client
self.name = f"semaphore:{name}"
self.max_tokens = max_tokens
self.ttl = ttl
async def acquire(self, timeout: float = 30.0) -> bool:
deadline = asyncio.get_event_loop().time() + timeout
while asyncio.get_event_loop().time() < deadline:
token = await self.redis.incr(self.name)
if token == 1:
await self.redis.expire(self.name, self.ttl)
return True
if token <= self.max_tokens:
return True
# Over limit — decrement and wait
await self.redis.decr(self.name)
await asyncio.sleep(0.5 + (token * 0.1)) # Progressive wait
return False
async def release(self):
await self.redis.decr(self.name)Simple. Effective. No external dependencies beyond Redis (which you're probably already using for caching).
How We Deployed This with Our Vietnamese Team
Our engineering hub in Can Tho handled the implementation. Why Can Tho? Because that's where we found senior engineers who understood distributed systems at depth — not just CRUD apps.
One of our lead engineers, a guy named Minh, pointed out something I'd missed: the semaphore TTL needed to be longer than the API call timeout. Otherwise, tokens would expire while agents were still waiting for responses, causing a token leak.
We set the TTL to 15 seconds. The API call averaged 2.3 seconds. That gave us a 12-second buffer. In 3 months of production, we saw zero token leaks.
The Results
Before the fix: 62% failure rate on the inventory API during peak loads.
After the fix: 0.4% failure rate — and those were genuine API downtime, not rate limiting.
More importantly, the agents stopped fighting each other. They queued gracefully. The system felt *calm* under load.
A Quick Comparison: Why Not Just Use a Queue?
You might ask: why not just push all requests through a message queue?
Fair question. But here's the problem: our agents weren't just making API calls. They were doing complex reasoning between calls. A queue would have serialized everything, killing throughput.
The semaphore approach let us control concurrency at the resource level while keeping agents independent. Each agent could still do its own thing — it just had to wait its turn for the shared resource.
What This Means for Your Multi-Agent Architecture
If you're building multi-agent systems, stop thinking of each agent as an island. They share infrastructure. Shared databases. Shared APIs. Shared GPU capacity.
You need three things:
- Distributed coordination — Redis, ZooKeeper, or etcd
- Graceful degradation — agents that can wait without crashing
- Observability — know exactly how many tokens each agent holds at any moment
We built a dashboard showing token utilization per agent. It looked like a stock market ticker. Fascinating to watch during a traffic spike.
The Broader Lesson
This isn't just about API rate limiting. It's about the hidden coupling in multi-agent systems. Your agents might be logically independent, but they're physically coupled through shared resources.
That's why "just add more agents" doesn't always work. You can't scale horizontally without scaling your coordination layer.
Our team in Vietnam — spread across Ho Chi Minh City and Can Tho — learned this the hard way. Now it's baked into every agent we build.
---
Frequently Asked Questions
Is a distributed semaphore better than a message queue for multi-agent systems?
It depends on your use case. Use a semaphore when agents need to maintain independence and do work between resource calls. Use a queue when you need guaranteed ordering and can afford serialization. For most production systems, you'll need both.
What happens if the Redis server goes down?
You need a fallback. We implemented a local mutex that activates when Redis is unreachable. It's less efficient but prevents a complete system halt. Also, run Redis in cluster mode with persistence.
How many concurrent agents can this approach handle?
We tested up to 500 concurrent agents with 50 tokens. The semaphore added about 2ms overhead per acquisition. The bottleneck becomes your Redis instance, not the semaphore logic. Use connection pooling to avoid that.
Do I need a dedicated Redis instance for the semaphore?
Not necessarily. We shared the same Redis instance used for caching. Just use a separate key namespace (we prefixed with `semaphore:`). Monitor CPU usage — if it spikes above 60%, consider a dedicated instance.
Related reading: Why Smart CTOs Hire Vietnamese Developers in 2025
Related reading: Vietnam Outsourcing: Why Smart Tech Leaders Are Moving Here in 2025







