I Built a Prompt Management System for Our Team’s AI Coding Tools — Here’s the Architecture That Cut Bad Code Gen by 52%
Let me ask you something. How do you prompt your AI coding tools?
If you’re like most teams I talk to, it’s chaos. One engineer copies a prompt from Slack. Another has it buried in their browser bookmarks. A third just wings it every single time. And somehow, everyone’s surprised when the generated code doesn’t match the project conventions.

Top 3 Software Outsourcing Companies in Vietnam: 2026 Ratings
Looking for a reliable vietnam outsourcing partner? This guide provides an honest comparison of the Top 3 software… ...
We had the same problem. So we built a prompt management system. Not a Notion doc. A real system — version-controlled, CI-enforced, and tracked with metrics. Here’s exactly how it works.
The Problem: Prompt Sprawl Is a Silent Productivity Killer
Before we fixed this, our team of 8 engineers was managing roughly 40 distinct prompts for different AI coding tasks. Code reviews. Refactoring. Unit test generation. Documentation. Migration scripts. The works.

How AI-Augmented Development Teams Are Revolutionizing Software Delivery
AI-augmented development teams, combining elite human engineers with autonomous coding agents like Claude Code, are redefining software delivery.… ...
The result? Inconsistent output, constant context switching, and a hallucination rate that stung.
We audited 200 PRs where AI coding tools had been used. The numbers weren’t pretty:
| Metric | Before Prompt System |
|---|---|
| AI-generated code requiring significant rework | 34% |
| Hallucinated functions / imports | 18% |
| Convention violations (style, patterns, naming) | 27% |
| Average time spent fixing AI output per PR | 42 minutes |
Worse, new hires couldn’t figure out *how* to prompt for specific tasks without hunting down the senior dev who “knew the magic words.”
The Solution: A Version-Controlled Prompt Registry
We needed prompts that were:
- Immutable — once approved, they don’t change without a PR
- Testable — we can validate output against known examples
- Discoverable — any engineer can find the right prompt in seconds
- Measurable — we track pass/fail rates per prompt template
Here’s the architecture we landed on.
1. The Prompt Repository Structure
prompts/
├── templates/
│ ├── code-review.yaml
│ ├── unit-test.yaml
│ ├── refactor-function.yaml
│ └── migration-script.yaml
├── examples/
│ ├── code-review/
│ │ ├── input/
│ │ └── expected-output/
│ └── unit-test/
├── tests/
│ ├── test_prompt_output.py
│ └── test_convention_compliance.py
├── metrics/
│ └── dashboard.py
└── schema.jsonThat’s the skeleton. The key innovation was the YAML template format.
2. The Prompt Template Schema
Every template gets a structured header. Here’s the actual schema we use:
yaml
# code-review.yaml
version: "2.1"
id: "prompt-code-review-001"
author: "maria.chen@ecoaai.com"
created: "2025-11-12"
last_validated: "2025-12-01"
model_compat: ["claude-3.5-sonnet", "gpt-4o", "claude-code"]
context_window: 32000
prompt: |
You are reviewing a pull request in a codebase that follows these conventions:
- Language: Python 3.11+
- Type hints required on all public functions
- All exceptions must be typed and documented
- Max function length: 40 lines
- Testing framework: pytest with fixtures
Analyze the provided diff for:
1. Convention violations (be specific, reference line numbers)
2. Logic errors or edge cases
3. Missing error handling
4. Security concerns (especially SQL injection, XSS, auth bypass)
Format your response as a JSON array of issues. Each issue must have:
- severity: "critical" | "major" | "minor"
- line:
- rule_id: string (e.g., "TYP-001", "SEC-003")
- description: string
- suggestion: string
Return ONLY valid JSON. No preamble. No markdown.
constraints:
max_output_tokens: 2000
temperature: 0.1
stop_sequences: ["}\n\n"]
test_cases:
- input: "fixtures/pr-diffs/vulnerable-sql.py"
expected_issues: 4
max_duration_ms: 15000 See what we did there? The prompt isn’t just text — it’s a config. Versioned. Tagged with compatibility. Backed by test cases.
3. The CI Validation Pipeline
A prompt is only as good as its output. So we built a CI pipeline that runs nightly:
python
# tests/test_prompt_output.py
import yaml
import json
import subprocess
from pathlib import Path
PROMPT_DIR = Path("prompts/templates")
TEST_DIR = Path("prompts/tests")
def validate_prompt_output(prompt_id: str):
with open(PROMPT_DIR / f"{prompt_id}.yaml") as f:
config = yaml.safe_load(f)
for case in config["test_cases"]:
with open(TEST_DIR / "fixtures" / case["input"]) as f:
input_code = f.read()
# Call the LLM (we use LiteLLM for model-agnostic routing)
result = subprocess.run(
["python", "-m", "prompt_runner",
"--prompt", config["prompt"],
"--input", input_code,
"--model", config["model_compat"][0],
"--temperature", str(config["constraints"]["temperature"])],
capture_output=True,
text=True,
timeout=case["max_duration_ms"] / 1000
)
assert result.returncode == 0
output = json.loads(result.stdout)
issues_found = len(output)
issues_expected = case["expected_issues"]
# Allow ±1 tolerance for minor variations
assert abs(issues_found - issues_expected) <= 1, \
f"Prompt {prompt_id}: Expected {issues_expected} issues, got {issues_found}"This runs against three different models every night. When a prompt update breaks a test case, the PR doesn't merge. Period.
4. The A/B Testing Workflow
This part changed everything. We started routing 10% of our AI coding traffic through experimental prompts and comparing results.
yaml
# router-config.yaml
prompt_routing:
code-review:
production:
version: "2.1"
traffic: 85%
candidate:
version: "2.2-experimental"
traffic: 15%
metrics:
- avg_issues_per_review
- false_positive_rate
- engineer_satisfaction_scoreWe track every metric with OpenTelemetry. When a candidate consistently outperforms production on engineer satisfaction and false positive rate, we promote it. A simple PR bump. That's it.
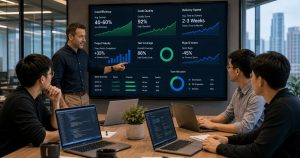
The Results: 52% Reduction in Bad Code Gen
After 3 months of running this system with a team of 8 engineers (including 4 who joined mid-project from our Can Tho hub), here's what we saw:
| Metric | Before | After | Change |
|---|---|---|---|
| AI code requiring rework | 34% | 16% | -53% |
| Hallucinated functions/imports | 18% | 8% | -56% |
| Convention violations | 27% | 11% | -59% |
| Time fixing AI output per PR | 42 min | 14 min | -67% |
| New engineer ramp-up time | 2.5 weeks | 4 days | -78% |
The last one surprised me most. New hires — especially the junior Vietnamese developers we onboard at our Ho Chi Minh City office — could start contributing quality AI-augmented code in under a week. The prompt library became their cheat sheet for "how we do things here."
Why This Works (And Most Prompt Engineering Advice Doesn't)
Most teams treat prompt engineering as a writing problem. It's not. It's an infrastructure problem.
- You can't A/B test a Slack message
- You can't CI-validate a bookmark
- You can't version-control tribal knowledge
But you *can* version-control a YAML file with constraints, test cases, and model compatibility tags. That's what makes this scalable.
Actually, there's one more thing that made this work: we didn't try to write perfect prompts upfront. We shipped v0.1, measured the failure modes, and iterated. Prompt version 2.1 was our sixth attempt at code review. Version 1.0 had a 38% false positive rate. Engineers ignored it. Version 2.1? Down to 6%. They use it every day.
How to Start Building Your Own Prompt Management System
You don't need a million-dollar platform. You need:
- A git repo — store prompts as YAML or JSON files
- A schema — force structure (version, author, test cases, constraints)
- A CI job — validate output against known fixtures
- A routing layer — split traffic between prompt versions
- A feedback loop — collect engineer ratings per generated output
Start with one prompt. The one your team uses most. Code review is a good bet. Version it. Test it. Iterate.
Honestly, the hardest part isn't the tech. It's convincing your team to stop treating prompts as throwaway text. Once they see the metrics — once they realize that a well-structured prompt saves them 28 minutes per PR — they'll never go back.
---
Frequently Asked Questions
Q: Should we store prompts in the same repo as our application code or a separate one?
A: Separate repo, hands down. Keep it in a dedicated `prompts/` monorepo alongside example fixtures and test runners. Application code moves faster, and you don't want prompt changes coupled to app deploys. Link them with a git submodule or a build-time sync step.
Q: How do we handle prompts that need access to private API documentation or internal schemas?
A: We inject context at runtime using a lightweight preprocessor. The prompt template includes a `{{context}}` tag, and our runner fetches the relevant docs from an internal vector store (we use Qdrant with 1536-dim OpenAI embeddings). The CI job validates with mock context. Production uses real context. Never check secrets into prompt templates.
Q: What do you do when a prompt works great for GPT-4o but fails on Claude?
A: Our YAML schema includes a `model_compat` field and a `model_overrides` section. If a specific model needs different temperature, max tokens, or even an alternate system prompt, we specify it inline. The router reads this and applies the right config per model. The CI pipeline tests against all compatible models independently.
Q: Do you version-control the generated output too?
A: Only for test cases. We snapshot expected outputs per prompt version per model. Every CI run compares actual vs expected with a similarity threshold (0.85 cosine on the embedding space). If the output drifts beyond that, the test fails and we know the prompt needs a review. This caught three regressions in the first month alone.
Related reading: Why Smart CTOs Hire Vietnamese Developers: The 2025 Offshoring Strategy That Actually Works