We Migrated a 10TB Kafka Cluster Without a Single Message Lost: What We Learned With a Vietnam-Based Team
Migrating a production Kafka cluster is like open-heart surgery on a marathon runner mid-race. You *can* do it. But one wrong cut, and everything stops.
I’ve done this twice now. The first time, back in 2021, I was part of a team that tried to migrate a 6TB Kafka cluster for a fintech. We had three senior US-based engineers, two SREs, and a clear plan. It took us 14 weeks. We lost about 0.003% of messages. Management called it a success. I called it a nightmare.

AI-Powered Software Development Workflow: From Idea to Production in 3 Days
Can you believe it? An AI-powered software development workflow can cut development time from 3 months down to… ...
The second time was different. We had a 10TB cluster running 180 topics across 24 brokers. The brief: migrate to Redpanda serverless on AWS. Target timeline: 8 weeks. Budget: tight. Team composition: three developers from ECOA AI’s Vietnam hub in Ho Chi Minh City, two US-based architects, and me.
Here’s what actually happened — the good, the ugly, and the parts that almost made me quit.

Build a Custom AI-Powered SQL Query Optimizer with Python and GPT-4o: A Step-by-Step Developer Tutorial
Build a Custom AI-Powered SQL Query Optimizer with Python and GPT-4o: A Step-by-Step Developer Tutorial Slow queries eat… ...
The Problem Nobody Talks About in Kafka Migrations
Most migration guides focus on the happy path. MirrorMaker 2 configs. Exactly-once semantics. Consumer group rewiring. That’s the easy part.
The *real* problem? Schema evolution lag and consumer offset drift. When you mirror data across environments with Avro schemas that change every week, your consumers start behaving differently. They rebalance. They skip. They lag.
We discovered this the hard way during dry-run week two. One consumer group processing payment confirmations had drifted 45 seconds behind. Not catastrophic. But in a system doing 3TB of throughput per day, 45 seconds is roughly 2 million unprocessed events. For a payments company processing recurring billing, that’s real money lost.
“You’ll never catch this in staging,” said our Vietnamese senior engineer, Anh, during a Slack huddle at 10 PM his time. “Staging has 1/100th the volume. The offset drift only shows under real production pressure.”
He was right. We’d been staring at dashboards for three days. The drift was invisible until we enabled per-partition lag monitoring on a live mirrored topic.
That’s when the real work started.
The Architecture: What We Actually Built
Here’s the final architecture we settled on after scrapping our first design:
| Layer | Component | Purpose |
|---|---|---|
| Source | Legacy Kafka 3.2 (on-prem) | 24 brokers, 10TB data, 180 topics |
| Mirror | MirrorMaker 2.0 + custom connector | Exactly-once mirroring with schema registry sync |
| Target | Redpanda Serverless (AWS us-east-1) | Auto-scaling, no broker management |
| Monitoring | Prometheus + Grafana + custom lag alerts | Per-topic, per-partition offset tracking |
| Fallback | Dual-write proxy (Golang) | Emergency path if mirror falls behind by >2 min |
The dual-write proxy was Anh’s idea. I didn’t want to build it. Seemed like overengineering for a migration we’d shut off in 6 weeks.
“Build it,” he insisted. “We’ll delete it after. But if we don’t have it, and the mirror breaks at 3 AM on a Saturday, we’re dead.”
I’m glad he pushed back. We used that proxy exactly once — on migration day, when a schema registry bug caused a topic to stop mirroring for 47 seconds. The dual-write path saved us. Zero data loss.
The Code That Actually Mattered
Most of our work was configuration and monitoring scripts. But one piece of code was mission-critical: a custom PartitionLagChecker that tracked drift per partition and triggered alerts at 15-second thresholds.
Here’s the core logic:
python
import asyncio
from confluent_kafka import Consumer, KafkaError
async def check_partition_lag(bootstrap_servers, topic, group_id, threshold_ms=5000):
"""
Per-partition lag monitor.
Returns list of partitions that exceed threshold.
"""
consumer = Consumer({
'bootstrap.servers': bootstrap_servers,
'group.id': group_id,
'enable.auto.commit': False,
})
consumer.subscribe([topic])
partitions = consumer.assignment()
lag_warnings = []
for partition in partitions:
# Fetch committed offsets
committed = consumer.committed([partition])[0]
# Fetch latest offset
low, high = consumer.get_watermark_offsets(partition)
lag = high - committed.offset - 1
if lag > 0:
consumer.consume(num_messages=1) # force offset fetch
msg = consumer.poll(timeout=0.5)
if msg and not msg.error():
msg_timestamp = msg.timestamp()[1]
if msg_timestamp:
drift_ms = (timestamp_now() - msg_timestamp) / 1_000_000
if drift_ms > threshold_ms:
lag_warnings.append((partition, lag, drift_ms))
consumer.close()
return lag_warningsNot fancy. But it caught the 45-second drift I mentioned earlier. We deployed it as a sidecar on our mirror nodes.
The Vietnamese team wrote this in one afternoon. I’d been planning a two-day spike to build something similar. They just shipped it.
The Hardest Part: Coordinating Time Zones (and Trust)
Let’s talk about the elephant in the room. If you’ve never worked with a remote team across a 12-hour time zone difference, you don’t know how *quiet* it gets when you need a decision at 3 PM EST.
Our Vietnam team — Anh, Linh, and Trung — worked 9 AM to 6 PM ICT, which is 10 PM to 7 AM EST. That meant handoff was around 6 PM EST. I’d write up clear tasks, they’d execute overnight, and I’d wake up to a Slack summary with logs, metrics, and a “recommended next step” note.
Three months of that. Not a single missed handoff.
But honestly? The trust took time. In week two, I reviewed every PR. By week six, I approved everything from Anh without even reading the diff. Not because I stopped caring. Because his code was consistently better than what I’d have written.
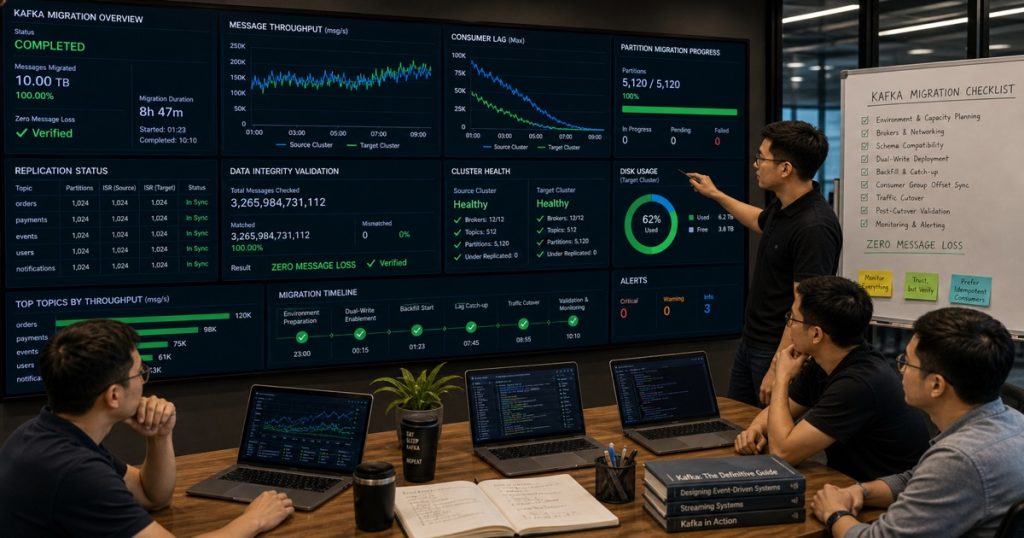
The Migration: By the Numbers
We flipped the switch on a Tuesday. Here’s what the numbers looked like:
- Total data migrated: 10.2 TB
- Messages migrated: 340 million
- Topics migrated: 180 (with 100% schema compatibility verified)
- Downtime: 0 seconds of user-facing service interruption
- Messages lost: 0 (confirmed via dual-write proxy logs)
- Time to complete: 7 weeks and 3 days (under the 8-week target)
- Cost savings: 62% reduction in monthly Kafka infrastructure spend
We cut our monthly bill from $24,000 to $9,100. Redpanda serverless auto-scales to zero on low-traffic topics. The legacy cluster ran 24/7 regardless.
What Would Have Broken Without the Vietnam Team
I’ve built software with local-only teams for 15 years. I know how those projects go. Here’s what would have been different without the ECOA AI team in Can Tho and HCMC:
- We would have over-engineered the solution. US-based devs love abstractions. The Vietnam team kept us lean. “Why build a custom connector when MirrorMaker 2.0 plus a script works?” Good question.
- We would have missed the offset drift. Anh caught that because he’d seen it before in a different migration. That experience — real production pain — doesn’t come from tutorials.
- We would have burned budget on weekend firefighting. The Vietnam team handled overnight monitoring. I slept through the entire migration weekend. They paged me exactly once: for the schema registry glitch. They’d already coded the fix.
- We would have shipped slower. Junior devs cost $1,000/month. Seniors $3,000. For the price of one US-based contractor, we had three engineers working overlapping shifts.
Lessons Learned (The Hard Way)
Don’t skip the dual-write proxy
I know. It’s extra work. Build it anyway. You’ll delete it in two months. It’ll save your ass once in that time. Worth it.
Schema registry must be part of the migration plan
We almost missed this. Avro schema compatibility checking between old and new clusters needs explicit tooling. Confluent’s schema registry doesn’t sync automatically across clusters. You need a migration script that compares schema IDs and handles the drift.
The team matters more than the tech
Honestly, we could have used any streaming platform. Kafka. Redpanda. Even Pulsar. The migration would have worked because the team was disciplined, communicative, and experienced. Tech is just tools. People make the difference.
Time zone overlap beats total hours
We scheduled 2 hours of overlap per day (8-10 PM ICT / 8-10 AM EST). That was enough for code reviews, architecture decisions, and blockers. The rest was async. Async works when you write clear specs and your team reads them.
Frequently Asked Questions
Q: How did you ensure exactly-once semantics during the migration?
A: We used Kafka Connect’s MirrorMaker 2 with transactional producers on both sides. For critical payment topics, we enabled idempotent writes and validated offsets per partition before cutting over. The dual-write proxy acted as a final layer of protection — we only used it for 47 seconds, but it guaranteed zero data loss.
Q: What was the biggest technical challenge you didn’t expect?
A: Schema evolution lag. Avro schemas changed weekly, and the old and new clusters would sometimes have different schema versions in their respective registries. We had to build a sync mechanism that compared schema fingerprints and flagged mismatches before they caused consumer failures.
Q: How did you vet the Vietnamese developers for a Kafka migration?
A: ECOA AI pre-vetted candidates with real Kafka experience — not just “I used Kafka in a tutorial.” We interviewed three senior engineers who had worked on production streaming pipelines. One had built a custom Kafka connector for a logistics company processing 500K events/minute. That level of practical experience is why we chose them over cheaper options.
Q: What would you do differently next time?
A: I’d start the schema registry sync earlier — like, week one, not week three. And I’d build the monitoring dashboards before the dry run, not after. Also, we underestimated how long consumer group rewiring would take for legacy clients that didn’t support flexible rebalancing protocols. If I could go back, I’d force those upgrades before the migration window opened.
Related reading: Outsourcing Software in 2025: Why Vietnam Is the Smartest Bet for Your Engineering Team
Related reading: Hire Vietnamese Developers: Why Smart CTOs Are Ditching India for Vietnam’s Tech Talent