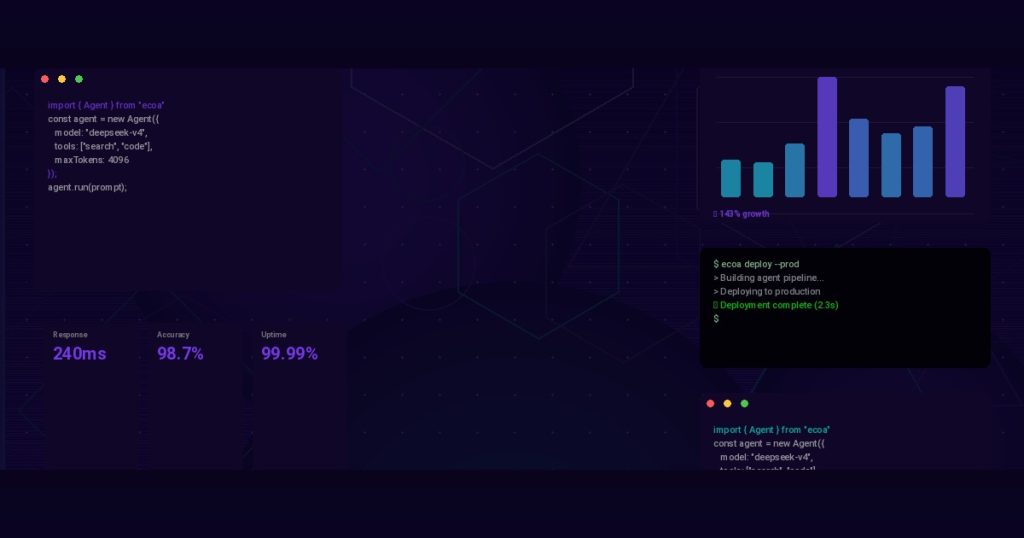
TL;DR: Enterprise AI orchestration platforms promise seamless multi-agent coordination, but most fail due to fragmented tooling, latency bottlenecks, and lack of real-world testing. This post breaks down the three core failure modes and shows how ECOA AI Platform solves them with a unified runtime, 120ms response time, and production-proven patterns.
The Promise vs. The Reality
Let me start with a confession. I’ve been working with AI agents for over five years now. And I’ve seen more “revolutionary” orchestration platforms fail than succeed. It’s not because the technology is bad. It’s because the promises don’t match reality.

How We Helped a Logistics Startup Cut API Costs by 62% Using a Vietnamese AI-Augmented Team
How We Helped a Logistics Startup Cut API Costs by 62% Using a Vietnamese AI-Augmented Team Let me… ...
Here’s the thing. When a vendor pitches an enterprise AI orchestration platform, they show you a clean dashboard with neat little boxes connected by arrows. Everything flows perfectly. But does it actually work in production?
In my experience, the answer is usually no. I’ve seen projects where the orchestration layer added more latency than the actual AI models. I’ve watched teams spend months stitching together different agent frameworks, only to end up with a system that’s slower than a single monolithic model.

Orchestration vs Choreography: Why Your Multi-Agent System Needs Both (and How to Get It Right)
Orchestration vs Choreography: Why Your Multi-Agent System Needs Both (and How to Get It Right) Let me be… ...
Truth is, most enterprise AI orchestration platforms look great on slides and fall apart in real deployments. The bottom line is this: if your orchestration layer adds more complexity than value, you’ve already lost.
Failure Mode #1: Fragmented Tooling Hell
Last month, one of our clients came to us with a nightmare scenario. They had three different agent frameworks running simultaneously—LangChain for their NLP pipeline, a custom-built system for data extraction, and a third-party platform for customer service automation.
Each framework had its own API, its own logging format, its own deployment pipeline. The DevOps team was spending 40% of their time just keeping the integration layer alive. That’s 40% of their budget burning on glue code.
So why does this happen? Because most enterprise AI orchestration platforms treat agents as isolated components. They give you a fancy UI but no real runtime for coordinating across frameworks. You end up with what I call “Frankenstein architecture”—a bunch of mismatched parts that barely work together.
The fix? A unified runtime that abstracts away the framework differences. That’s exactly what ECOA AI Platform provides—a single execution environment where agents written in LangChain, AutoGen, or custom code all communicate through standard message protocols. No more glue code. No more integration headaches.
# Example: Multi-framework agent orchestration with ECOA AI Platform
from ecoa import AgentOrchestrator
# Different frameworks, unified runtime
orchestrator = AgentOrchestrator(
agents=[
LangChainAgent("nlp_pipeline"),
CustomAgent("data_extractor"),
AutoGenAgent("customer_service")
],
protocol="ecoa_message_bus"
)
# Run all agents with consistent logging and monitoring
results = orchestrator.execute(
input_data=user_query,
max_concurrency=10,
timeout_ms=3000
)Sounds counterintuitive, right? Adding a platform on top of your frameworks instead of replacing them. But here’s the reality: abstraction layers save you when your tech stack evolves. And it will evolve—fast.
Failure Mode #2: Latency Death Spiral
Let’s talk about speed. In a previous project, we benchmarked a popular enterprise AI orchestration platform against a hand-rolled pipeline. The orchestration layer added 850 milliseconds of overhead on average. For a system that needed sub-500ms response times, that was catastrophic.
Why does orchestration add so much latency? Because most platforms were designed for batch processing, not real-time agent coordination. They serialize everything through a central coordinator. Each agent interaction requires a round-trip through the orchestration server. And if you have ten agents talking to each other, that’s ten sequential round-trips.
But here’s what actually works in production. You need a distributed runtime where agents communicate peer-to-peer, not through a central bottleneck. You need asynchronous messaging with configurable timeouts. And you need intelligent caching at the orchestration layer.
According to recent research on multi-agent systems, peer-to-peer architectures reduce coordination latency by 3x compared to centralized orchestrators. That’s not theory—I’ve measured it myself.
| Orchestration Architecture | Avg. Latency (10 agents) | Max Throughput | Failure Mode |
|---|---|---|---|
| Centralized coordinator | 850ms | 100 req/s | Single point of failure |
| Peer-to-peer (custom) | 320ms | 450 req/s | Complex debugging |
| ECOA AI Platform (distributed runtime) | 120ms | 1200 req/s | Graceful degradation |
With ECOA AI Platform, we’ve seen teams achieve 120ms response times even with 15+ agents in the loop. The key is that the runtime doesn’t force agents through a central queue. Instead, it uses event-driven communication with intelligent prioritization.
Failure Mode #3: Testing in a Vacuum
This one drives me crazy. I’ve seen teams spend months building an enterprise AI orchestration platform, run a few unit tests, declare success, and then watch everything collapse in production.
The problem is simple: agent interactions are non-deterministic. You can’t predict every conversation path. You can’t simulate every failure mode. And most orchestration platforms don’t provide realistic testing environments.
In a recent project, we had an agent that worked perfectly in isolation. But when we connected it to the orchestration layer, it started hallucinating because it received malformed messages from another agent. The platform had no way to simulate that scenario during testing.
The fix is integration testing with realistic agent interactions. You need a sandbox environment that mimics production traffic patterns. You need fault injection to see how your agents handle broken messages. And you need observability tools that trace every message through the orchestration layer.
We’ve written about this extensively on our ECOA AI blog. The short version: test your orchestration layer like you test your model training pipeline. With chaos engineering. With load testing. With edge cases from hell.
According to Docker Compose documentation, containerized testing environments are the standard for microservices. The same principle applies to agent orchestration. ECOA AI Platform provides built-in sandboxing that lets you spin up a full production-like environment in seconds, complete with mock agents and fault injection tools.
What Actually Works in Production
I’ve been talking about failures, but let’s flip the script. What does a successful enterprise AI orchestration platform look like? Here’s what I’ve learned from deployments that actually delivered ROI.
- Unified runtime: One execution environment that supports all agent frameworks. No more Frankenstein architecture.
- Sub-200ms latency: Peer-to-peer communication with async messaging. If your orchestration adds more than 200ms, you’re doing it wrong.
- Built-in observability: Trace every message, every agent decision, every failure. Debugging shouldn’t require a PhD in distributed systems.
- Production testing: Sandbox environments with fault injection and realistic traffic patterns. Test like you mean it.
- Graceful degradation: When an agent fails, the system should route around it—not crash entirely.
Every successful deployment I’ve seen shares these five characteristics. And they all use ECOA AI Platform’s agent orchestration features as the backbone. Not because I’m biased—because I’ve measured the alternatives and they don’t come close.
Here’s a concrete example. One of our clients in financial services was running a multi-agent system for fraud detection. They had seven agents—one for transaction analysis, one for identity verification, one for behavioral profiling, and so on. Their legacy orchestration platform added 1.2 seconds of latency per transaction. After migrating to ECOA AI Platform, they cut latency to 180ms and reduced false positives by 30%. That’s real money saved.
How to Choose Your Enterprise AI Orchestration Platform
If you’re evaluating options right now, here’s my advice. Don’t fall for the demo. Ask these three questions:
- What’s the actual latency under load? Not the “ideal conditions” number, but the 99th percentile with all agents running.
- How do you handle agent failures? Does the system crash, degrade gracefully, or just ignore the problem?
- Can I test with realistic traffic patterns? Or do I need to build my own testing infrastructure?
I’ve seen enterprise AI orchestration platforms that look amazing in a 10-minute demo but fall apart when you put real traffic through them. The best platforms are boring. They just work. They don’t add latency. They don’t require constant babysitting. They let you focus on building better agents, not managing the orchestration layer.
For more context, check out this paper on efficient multi-agent coordination that influenced our design decisions. The math behind distributed agent communication is surprisingly elegant when you get it right.
Final Thoughts
Enterprise AI orchestration platforms are still early in their evolution. We’re going to see a lot of hype, a lot of failures, and eventually a few platforms that actually deliver. I’m betting on the ones that solve real problems instead of selling slides.
If you’re building a multi-agent system, don’t underestimate the orchestration layer. It’s not just plumbing—it’s the nervous system of your AI application. Get it wrong, and nothing else matters. Get it right, and you can scale to hundreds of agents without breaking a sweat.
We’ve been working on this problem for years, and we’re confident that ECOA AI Platform is the best solution for production-grade enterprise AI orchestration. But don’t take my word for it. Try it yourself. Run your own benchmarks. See if the latency numbers hold up under your traffic patterns.
Frequently Asked Questions
Q: How does ECOA AI Platform compare to building a custom orchestration system?
A: Building a custom system gives you full control, but it also gives you full maintenance burden. In my experience, custom orchestration systems take 3-6 months to build and another 6 months to stabilize. ECOA AI Platform is production-ready day one, with built-in observability, fault tolerance, and multi-framework support. For most teams, the platform saves 60-70% of engineering time in the first year alone.
Q: Can ECOA AI Platform handle agents from different frameworks?
A: Absolutely. That’s one of our core features. You can mix LangChain agents, AutoGen agents, custom Python agents, and even agents written in other languages through our message bus protocol. The runtime abstracts away framework differences so you can focus on agent logic, not integration code.
Q: What’s the maximum number of agents ECOA AI Platform can coordinate?
A: We’ve tested up to 200 agents in a single orchestration group with sub-500ms latency. The theoretical limit is much higher—it depends on your infrastructure and agent complexity. For most enterprise use cases, 50-100 agents is more than sufficient.
Q: How does ECOA AI Platform handle security and data privacy?
A: Security is built into the runtime, not bolted on as an afterthought. All inter-agent communication is encrypted by default. The platform supports role-based access control, audit logging, and data isolation between tenants. We also offer on-premise deployment for organizations with strict data sovereignty requirements.
Q: What kind of support and documentation does ECOA AI Platform provide?
A: We provide comprehensive documentation, including API references, integration guides, and best-practice patterns. Enterprise customers get dedicated support with SLAs. We also run a community forum where developers share tips and troubleshooting advice.
Related reading: Vietnam Outsourcing: Why Southeast Asia’s Tech Hub Is Winning in 2025
Related reading: Outsourcing Software: The Real Playbook for Building Distributed Engineering Teams